


Aleksa Gordić je nedavno na svojoj LinkedIn stranici objavio pokretanje sopstvenog jezičkog modela na bazi veštačke inteligencije (AI), koji je nazvao YugoGPT. Ovaj inovativni proizvod pokazuje bolje rezultate prilikom upita na jezicima bivše Jugoslavije nego što je to slučaj sa nekim AI modelima velikih tehnoloških kompanija.
YugoGPT: Specijalizovani AI za jezike ex-YU
YugoGPT, koji podržava srpski, hrvatski, bosanski i crnogorski jezik, predstavlja više od običnog jezičkog modela; on je sveobuhvatna platforma namenjena razvoju i primeni veštačke inteligencije u regionu bivše Jugoslavije. Aleksa Gordić, sa iskustvom rada u Microsoftovom razvojnom centru Srbija i Googleovoj laboratoriji DeepMind, razvio je ovaj model koji ne samo da precizno razume i generiše tekst na lokalnim jezicima, već i nadmašuje performanse poznatih modela kao što su Mistral i LLaMA 2 kompanije Meta.
Ova superiornost YugoGPT-a ne samo da potvrđuje njegovu efikasnost u pružanju relevantnih odgovora korisnicima, već i naglašava njegov potencijal kao ključnog alata u prilagođavanju AI tehnologija specifičnim jezičkim i kulturnim potrebama regiona, obećavajući značajan napredak u lokalizaciji i primeni veštačke inteligencije.
Dalji razvoj i primena
Iako YugoGPT već pokazuje impresivne rezultate, Gordić navodi da proizvod zahteva dalje usavršavanje i da će biti znatno unapređen u narednih nekoliko meseci. Pored toga, Gordić je sa kolegom Tonijem Farmerom pokrenuo startap “Runa AI”, koji ima za cilj da pomaže firmama u rešavanju problema u oblasti obrade teksta. Ovo ukazuje na širu primenu YugoGPT-a i sličnih tehnologija u različitim industrijama, od obrazovanja do poslovanja.
Postavili smo pitanja Aleksi kako bi saznali nešto više o YugoGPT
WEBMIND: Koji su bili najveći tehnički izazovi tokom razvoja YugoGPT-a i kako ste ih prevazišli?
Aleksa Gordić: Prvi najveći problem je bio da razumem kako ću da nabavim veliku količinu GPU-ova za treniranje ovih sistema. Zbog moje pozicije u AI svetu to je bilo nešto lakše i uskoro se naredjalo više stranih kompanija koje su htele da mi daju svoje A100 GPU-ove na korišćenje. Zauzvrat, ja njih promovišem na socijalnim mrežama na kojima imam preko 160.000 pratilaca (takođe im znači i što sam “power user”).
Jedan od najvećih izazova pored manjka compute-a je bio takođe nedostatak testova za srpske/HBS LLM-ove. Tako da sam prethodnih nedelja napravio (uz pomoć ljudi sa mog Discord servera) i prvi srpski LLM skup evaluation testova.
I na kraju OpenAI GPT-4 krediti su dosta skupi ali srećom dosta entuzijastičnih i dobrih pojedinaca, kao i nekoliko kompanija, su pomogli i finansijski sa projektom.
WEBMIND: Šta vas je inspirisalo da razvijete YugoGPT i kako ste započeli ovaj projekat?
Aleksa Gordić: Mislim da mi se već godinu ili dve dana u glavi “krčka” ideja da bi bilo lepo da napravim nešto za naš region. To razmišljanje je kulminiralo nakon što sam napustio Google DeepMind, gde sam radio kao machine learning inženjer, i krenuo da razmišljam o tome šta dalje.
Ranije ovog leta sam hteo da uradim jedan fine-tune Meta-inog LLaMA jezičkog modela i skapirao da je podrška za naš(e) jezik(e) dosta loša. Ne samo da nema open-source ekosistema oko LLM-ova već i generalan nedostatak inteligentnih sistema za prevođenje (DeepL najbolji komercijalni provider ovih usluga recimo uopšte ne podržava srpski) i ostalih NLP sistema.
To me je inspirisalo da krenem da radim na open-source-ovanju rada od Mete (ex Facebook) koji se zove “no language left behind” odnosno “ni jedan jezik neće biti ostavljen iza” u mom slobodnom prevodu. Taj sistem podržava 202 jezika odnosno preko 40.000 pravaca prevođenja.
Kako sam radio na tom projektu skapirao sam da ono što stvarno hoću da uradim jeste da treniram LLM-ove za razne jezike i da želim da počnem sa našim jezicima.
Tako se rodila ideja yugoGPT-a, LLM-a od 7 milijardi parametara za HBS jezike (hrvatski, bosanski, srpski, crnogorski).
Inače razlog zašto podržavam baš ove jezike je prvenstveno tehničke prirode:
Slični su tako da ako model nauči jedan jezik lako će naučiti i drugi (transfer learning)
Da bih maksimizovao broj tekstualnih tokena (token je za sve praktične potrebe ovog bloga sinonim za reč)
Činjenica je da ne postoji dovoljno tokena za sve ove jezike na celom internetu da se istrenira jedan optimalan LLM, pa zbog toga mora da se krene od modela koji su pretrenirani na engleskom i uradi “continued pretraining”.
WEBMIND: Možete li nam dati primere kako YugoGPT već menja način na koji ljudi i organizacije u regionu koriste veštačku inteligenciju?
Aleksa Gordić: To je dobro pitanje, iskren odgovor je da nisam siguran. Mislim da će velika barijera biti sledeće tri stavke:
- Manjak GPU-ova od strane domaćih kompanija
- Manjak talenta / ljudi koji znaju da treniraju i fine-tune-uju ove modele
- Manjak svesti oko toga zašto je open source bitan – zbog ovoga mislim da će neke kompanije samo uzeti model, izgraditi nešto interno, i neće potom podeliti taj svoj rad sa zajednicom. Nažalost mnogo ljudi i dalju kada čuju open-source samo čuju “besplatno”.
Ukoliko ima kompanija koje bi želele da koriste ove velike jezičke modele ja ću nuditi tu uslugu narednih meseci kroz svoj startup Runa AI. Veliki broj use-case-eva koji su prethodno bili nerešivi mogu da se reše na ovaj način.
Takođe što se tiče i korisnika a ne samo biznisa, yugochat će stalno koristiti naš najbolji interni model!
WEBMIND: Na koji način pojedinci i organizacije mogu doprineti ili se uključiti u razvoj i primenu YugoGPT-a?
Aleksa Gordić: Što se tiče pojedinaca najbolji način je da se pridruže u moj Discord server jer ću tu kačiti sve vesti i tražiti pomoc od zajednice vezano za tehničke aspekte projekta.
Što se tiče organizacija jedna opcija je da me podrže finansijski, napisao sam ovaj Notion dokument da pojasnim kako stvari funkcionišu sa te strane.
Takođe ako imaju dobar use-case pozivamo organizacije da se pridruze na nas private beta.
WEBMIND: Kako YugoGPT nadmašuje postojeće jezičke modele poput Mistrala i LLaMA 2, posebno kada je reč o jezicima bivše Jugoslavije?
Aleksa Gordić: Rezultati koje sam skoro podelio na LinkedIn-u govore sami za sebe! 🙂
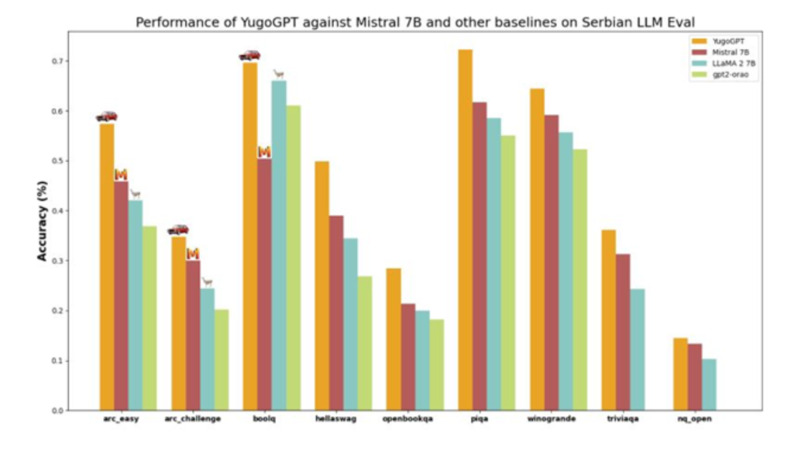
Izvor: Aleksa Gordić
Model je treniran nedeljama na superkompjuteru sa podacima za srpski, hrvatski, bosanski, i crnogorski jezik kako bi dosao do ovih rezultata.
Interni modeli koje sam u međuvremenu razvio imaju još bolje rezultate nego ovaj chart. Ti modeli se koriste i u okviru gorepomenutog yugochat-a.
Yugo pamtite kao automobil, a od sad kao GPT
YugoGPT predstavlja značajan korak napred u prilagođavanju AI tehnologija specifičnim jezičkim i kulturnim potrebama regiona bivše Jugoslavije. Sa kontinuiranim razvojem i unapređenjem, očekuje se da će ovakvi modeli imati široku primenu i značajno doprineti različitim aspektima društva. Kako se tehnologija razvija, važno je pratiti i podržavati inovacije koje pružaju alate prilagođene lokalnim potrebama i jezicima.
















